
Alig 200 óra alatt tanítottak meg magyarul egy mesterséges rendszert

Nagyjából 15 millió ember beszéli a világ közel 7,7 milliárd lakosából a magyar nyelvet, amivel jelenleg a 78. helyen állunk a világ nyelvei között. Azt nézve nem is olyan rossz hír ez, hogy bár biztos számot nehéz mondani, még most is jóval 6 ezer felett van a beszélt nyelvek száma a Földön. Az viszont természetes vágy ilyen méretű beszédközösségnél, hogy szívesen használnánk anyanyelvünket az informatikai világban is. Ahhoz azonban sajnos a 15 millió beszélő kevés, hogy a nagy cégeknek megérje kifejleszteni a magyarul beszélő szoftvereket.
Most azonban a Pécsi Tudományegyetem (PTE) Alkalmazott Adattudományi és Mesterséges Intelligencia-csapata a Microsoft Azure mesterséges intelligencia és az ONNX Runtime megoldások alkalmazásával megépítette és betanította saját BERT-large modelljét magyar nyelven, méghozzá kevesebb, mint 200 munkaóra és 1000 euró befektetésével - adják hírül a Microsoft honlapján közzétett közleményükben.
A nagy mennyiségű magyar nyelvű adat kezelését megkönnyítendő a PTE természetes nyelvfeldolgozási (NLP) módszerek kutatásába fogott.
„A Microsoft piacvezető a nyelvi modellek betanításának területén. Természetes, hogy a legjobb technológiát akartuk használni” - mondta el Hajdu Róbert, az Alkalmazott Adattudományi és Mesterséges Intelligencia Központ volt tervezőmérnöke.
Ahelyett, hogy gyenge minőségű adatokat gyűjtöttek volna az internetről, a Nyelvtudományi Kutatóközpont szakemberei segítségével készítették elő az alapokat. Az Azure pedig mindent megkönnyített és felgyorsított.
A modell működéséhez egyébként legalább 3,5 milliárd szót tartalmazó folyószöveg szükséges, ezt az adatbázist a Nyelvtudományi Kutatóközpont, a projekt másik résztvevője többek között a Magyar Nemzeti Szótárból, online médiatárakból és az opensubtitles.org ingyenesen hozzáférhető filmfelirat-adatbázis magyar nyelvű anyagai közül gyűjtötte a csapat.
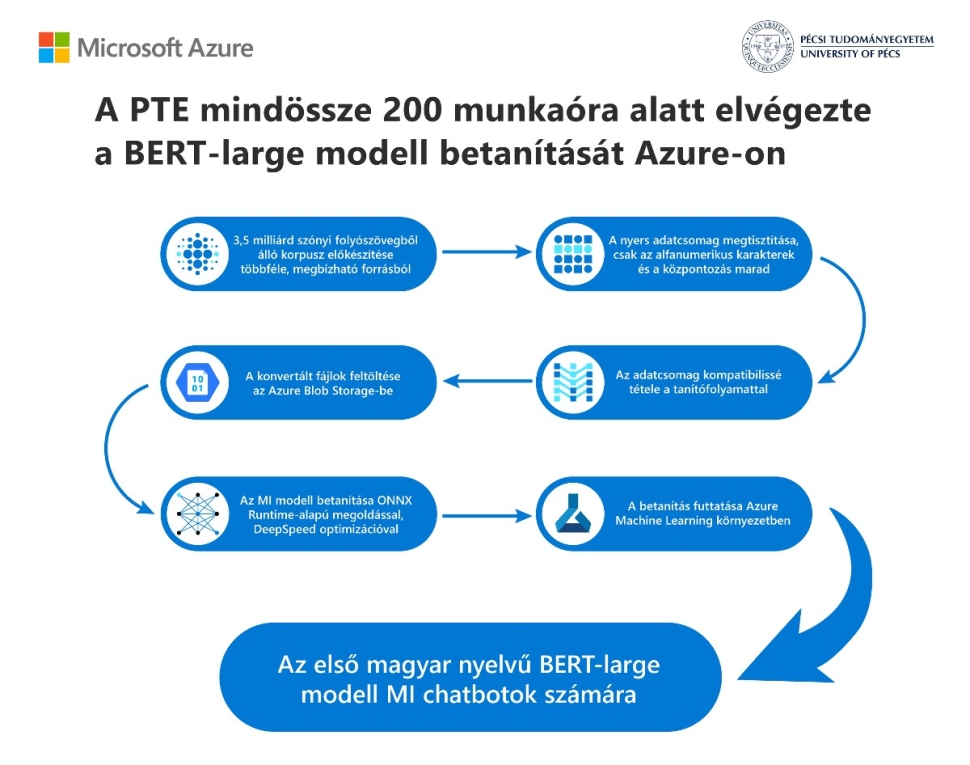
- mesélte Dr. Feldmann Ádám, a PTE Adattudományi és AI csoport vezetője. „Az ONNX Runtime nélkül a HILBERT-large modellünk betanítása 1500 órát, vagyis megközelítőleg két hónapot vett volna igénybe” – tette hozzá.
A Pécsi Tudományegyetem BERT-large modellje jelentős lehetőségeket rejt magában az írott és beszélt szöveg feldolgozása, az intelligens keresés, az entitásérzékelés, a dokumentációs klasszifikáció terén. A HILBERT közreműködhet újabb, jobb teljesítményű chatbotok létrehozásában is.
A projekt teljes, hosszabb ismertetőjét EZEN A LINKEN lehet elolvasni.
